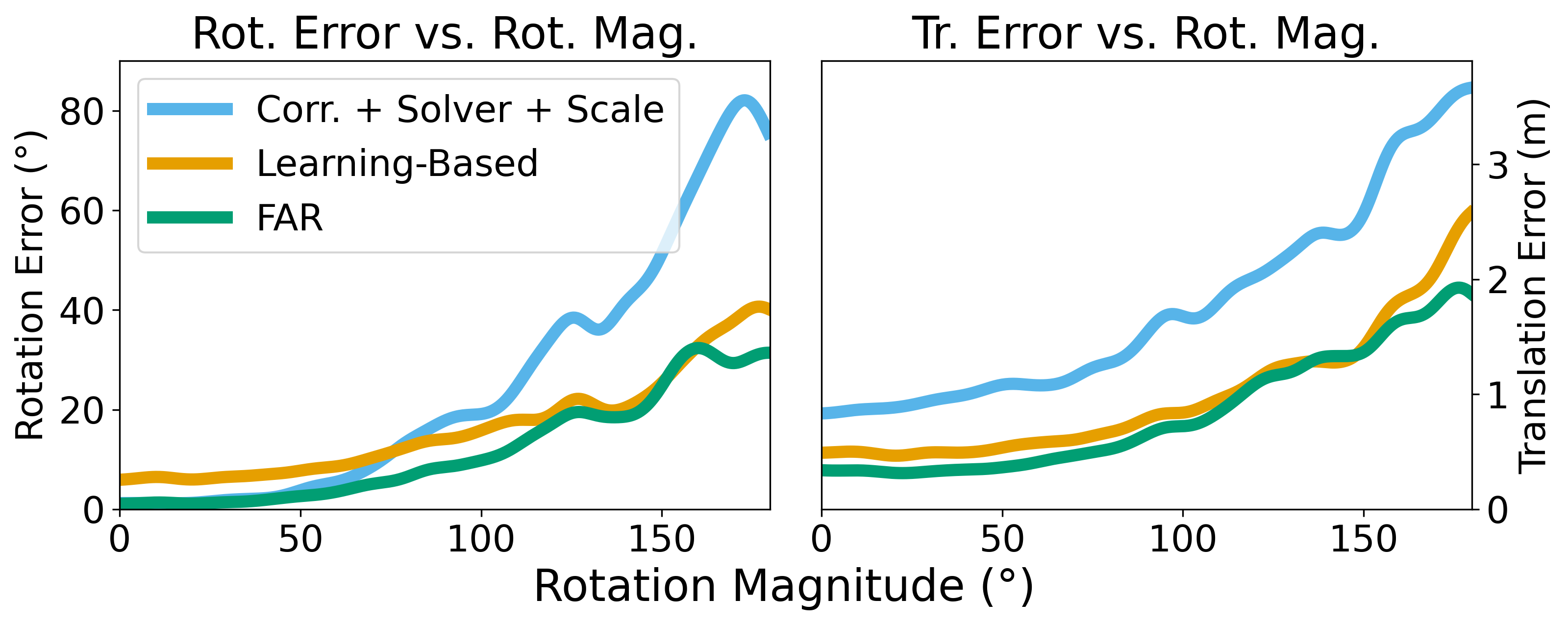
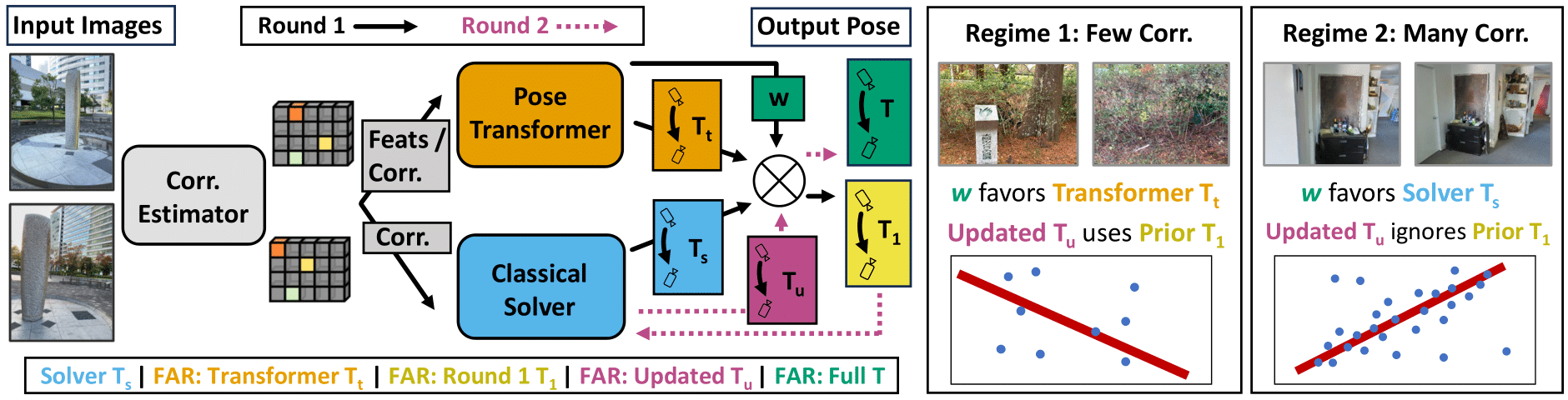
Estimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-Free Relocalization.
@inproceedings{Rockwell2024,
author = {Rockwell, Chris and Kulkarni, Nilesh and Jin, Linyi and Park, Jeong Joon and Johnson, Justin and Fouhey, David F.},
title = {FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation},
booktitle = {CVPR},
year = 2024
}